
The System Design Interview by Alex Xu tackles a lot of interesting topics from a conceptual perspective. It's not a reference manual, but rather a book that present ideas and solution schemes which others have had to face to be able to design some of the platforms that we currently use. In each chapter, a problem is presented and the solution is approached as a design process from scratch.
While my approach is more pragmatic and focused on gaining a deeper understanding, it is important to mention that the book's approach is to explain how to tackle a system design interview. Therefore, I will provide a brief summary of the techniques described in the book.
It is worth mentioning that this article is not meant to replace reading the book, I will not summarize the whole book.

Introductory concepts
In the system design, the participation of different, more or less complex components is required to solve the problem at hand. Therefore, it is necessary to know these components and what role they play in the system.
In this post, I will introduce some of the simplest concepts, let's call them introductory, that will be necessary to explain those that are more complex.
Single Point of Failure
For me, one of the most relevant concepts and one that deserves special attention is the Single Point of Failure (SPOF).
The Single Point of Failure can be defined as "the component that if it fails, it interrupts the system service". That is why it is very important to identify and eliminate SPOFs in a system, as they can have a significant impact on the availability and reliability of the system. A common way to mitigate SPOFs is to implement redundancy, that is, to have more than one component or system in operation to provide the same services. In this way, if one component fails, another backup component can take its place and ensure the continuity of the service.
Introductory Concepts for System Design
Some of the simplest concepts that, for me, are a good starting point to utterly understand the design of a system are the following:
- Vertical and horizontal scaling.
- Web, cache, and data tiers.
- Domain Name System (DNS).
- Data centers.
- Message queues.
- Logging, metrics, and automation.
Vertical and horizontal scaling
Scalability of systems is one of the most relevant topics when talking about systems that have growth expectations in the short, medium, and even long term or that simply have periodic work peaks. Traditionally, 2 types of scaling are defined as possible:
- Vertical scaling (scale up) is known as adding more processing power, storage, etc. to existing systems.
- Horizontal scaling (scale-out) is known as adding more resources (servers, databases, etc.) thereby increasing the number of elements within the system.
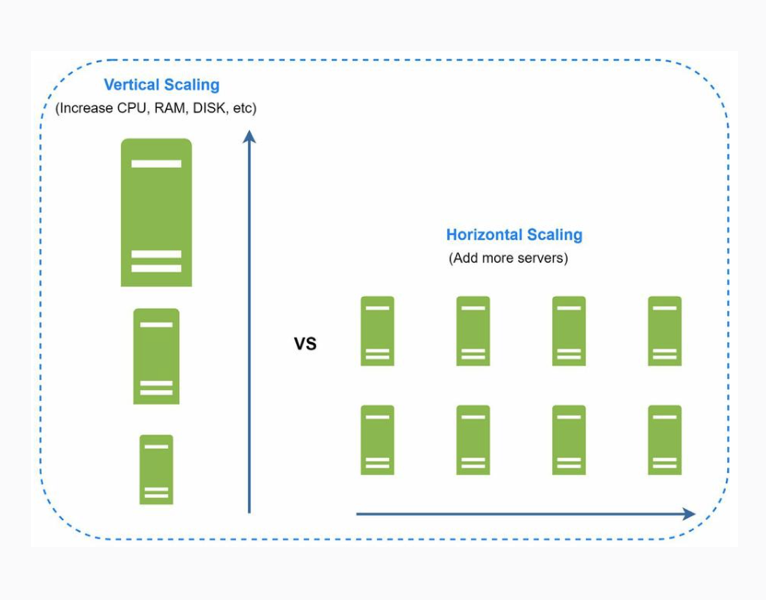
Each type of scaling has its advantages and disadvantages, but horizontal scaling is the most desirable for applications that require a larger scale. After all, by provisioning the system with more machines, SPOF is reduced.
Web, data, and cache tiers
It is a valid way to separate a complex system into simpler subsystems. In this way, the system as a whole can be conceptually and practically attacked individually and isolated.
Web tier
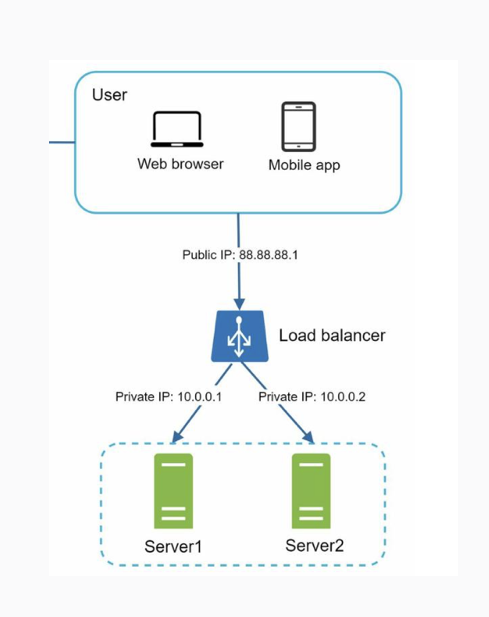
The web tier covers communication and traffic between clients (web / mobile) and servers. At this level, it is important to understand the following concepts:
- Load balancer is responsible for automatically distributing the workload (for example, traffic) among different servers or applications. Clients connect directly to the load balancer, which is responsible for distributing the traffic. A key piece when we want to reduce SPOF, as it will redirect all traffic to the available systems in case of a system failure.
- Stateful and stateless web tier. A stateful tier is one that remembers the data (state) between the different requests made to it. On the other hand, a stateless tier does not preserve this information. In stateful servers, each request from the same client has to be routed to the same server since its state persists in one place. On the other hand, in stateless servers, the storage part is decoupled, so any request can be handled by any server. Stateless systems are simpler, more robust, scalable, and mitigate SPOF to a certain extent.
Data tier
The data tier encompasses all that is related to database and persistent storage management. In this tier, it is important to understand the following concepts:
- Types of databases. They can be classified into relational and non-relational. In turn, non-relational can be subdivided into: key-value, graph, document,... among others. Non-relational databases can be interesting for certain requirements such as: low latency, unstructured data, serialized data (JSON, XML, YAML, ...) and massive data storage.
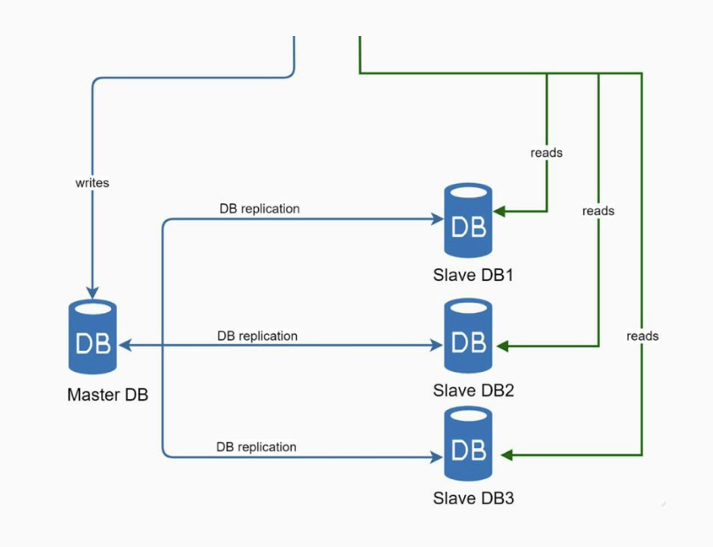
- Database replication. Database replication is a very common technique to offer increased fault tolerance and redundancy. Therefore, mitigating SPOF. The most well-known and used technique is the master-slave where generally the master supports write operations and the slaves support read operations.
- Database fragmentation, also known as sharding, is a technique that achieves greater scalability and decentralization by dividing data into smaller, more manageable databases.
Cache tier
If we want to offer good quality and loading and response speed, these two components are essential: a cache tier and a CDN.
The cache tier contains all those data storage components, generally of a temporary nature, more critical in terms of speed and availability. The data that is stored in the cache level is frequently used or requires being consulted as quickly as possible.
It is important to consider when to use cache, with what expiration policy, how to maintain consistency, how to mitigate failures and, in some cases, what replacement policy to use. Implementing a good cache level provided with multiple subcomponents reduces the SPOF.
Content Delivery Network
Although a Content Delivery Network (CDN) technically does not belong to the cache level, functionally it is. After all, a CDN is a cache of static content: images, videos, files,...
As with the cache, it is important to consider in what cases to use it due to the economic cost associated with it, what expiration policy to use, what to do in case of failure, what invalidation policy to use and with what criterion,...
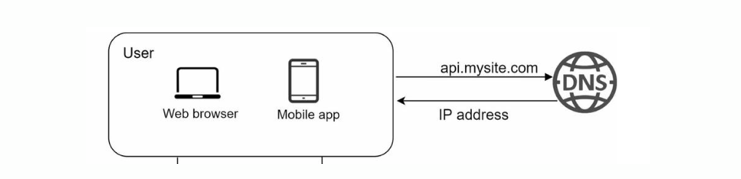
Domain Name System (DNS)
The Domain Name System (DNS) is a domain name management system on the Internet. Its main function is to translate (resolve) domain names into IP addresses, allowing users to access websites by typing domain names instead of IP addresses.
Data Centers
A data center is a location dedicated to hosting and maintaining servers and other subsystems partially or completely.
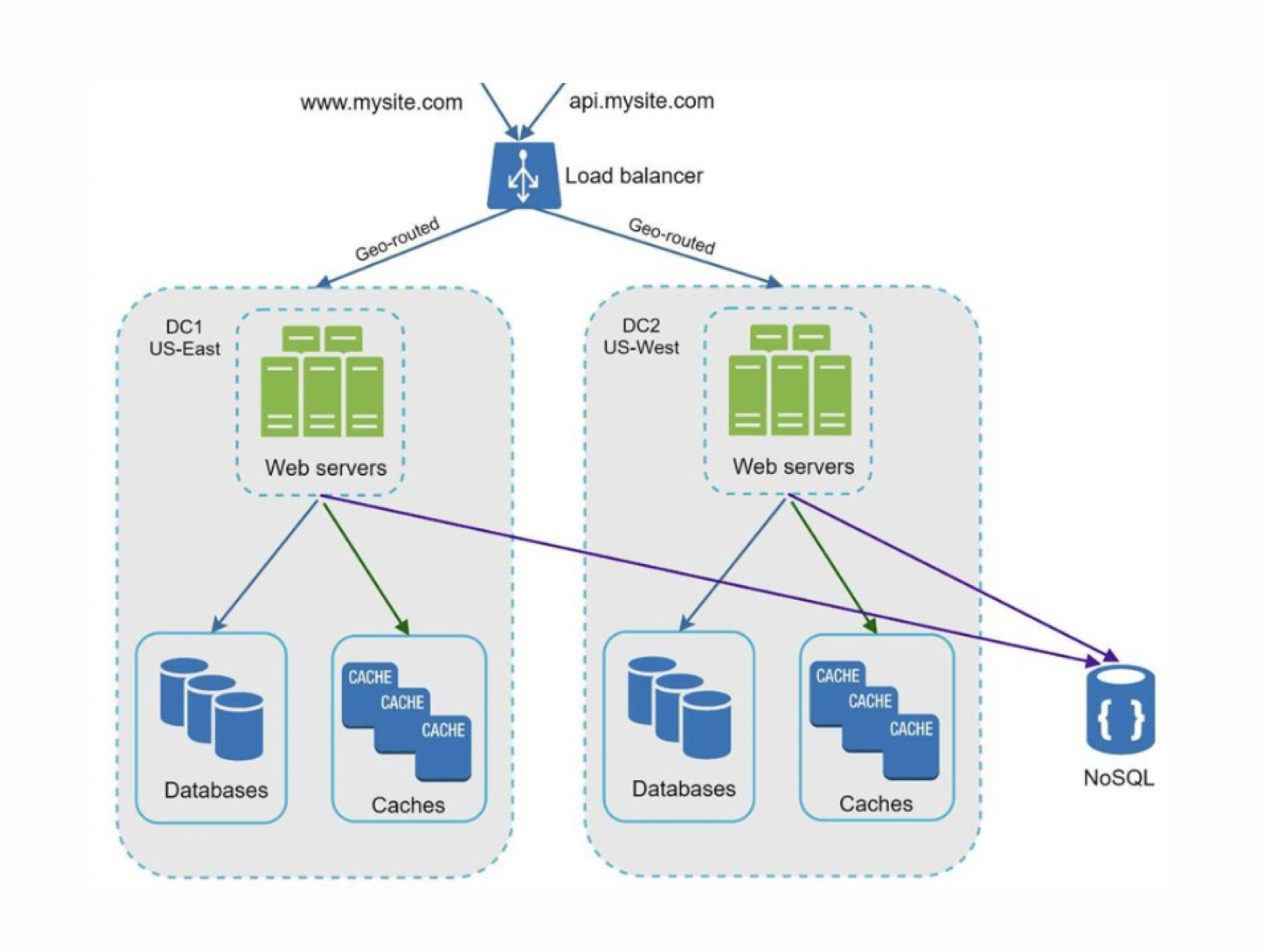
The most relevant here is what it offers by applying redundancy to these. By having more than one data center, if one or more of these goes out of service, operations can still be offered. It should be noted that for this to be effective, there must be a decoupling of various components of the system so that they can scale independently, thus reducing the SPOF.
Message Queues
Message queues are a key component for the asynchronous communication of system components, reducing coupling between these components.
A message queue-based architecture has components that produce messages (producers) and components that consume them (consumers). Producers publish messages on the queue and subscribed consumers consume them.

This design pattern reduces coupling within the architecture, helping to build more scalable and reliable systems, thereby reducing the SPOF.
Logging, metrics, and automation
As the system and product grows, it is necessary to invest time in developing these essential tools:
- Logging, recording system errors helps to identify and resolve them more effectively.
- Monitoring, collecting information about the system and product can help understand and plan the next steps to grow the project.
- Automation, with the growth of the system and product, certain tasks need to be automated to increase the productivity of both the product and the development team.
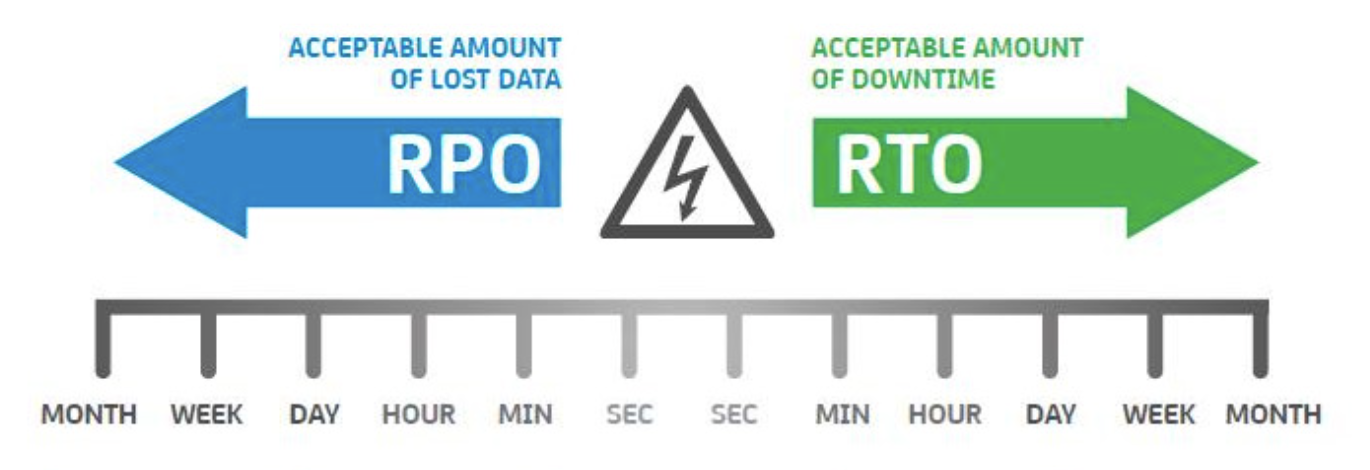
RPO y RTO
When a failure occurs in our system, it is important to take into account these two concepts:
- RPO (Recovery Point Objective). This is the point in time to which data must be recovered in case of a failure. Therefore, it is the amount of time or volume of data that a system can afford to lose in case of an incident. To mitigate this, it is necessary to have backups and/or data replication. Everything will depend on the type and nature of the business.
- RTO (Recovery Time Objective). This is the estimated time it will take to recover the system after a failure. Therefore, it is the deadline by which the system is expected to be operating again after an incident. To mitigate this, it is necessary to have an incident recovery plan supported by redundancy systems and data restoration.
Learning
These are the most basic concepts you need to know before venturing into designing a system. If you want to read and learn more about this topic, this post mainly refers to the chapter: "Chapter 1: Scale from zero to millions of users". You can get the book here.