
En System Design Interview por Alex Xu se abordan muchos temas interesantes desde una perspectiva conceptual. No es un manual de consulta per sé. Es un libro en el que encontrarás ideas y esbozo a soluciones por las que otros, muy probablemente, han tenido que pasar para diseñar sistemas que usamos en nuestro día a día. En cada capítulo del libro se plantea un problema y se aborda la solución como un proceso de diseño desde 0.
Aunque mi enfoque es más didáctico y con afán de obtener un entendimiento más profundo de sistemas conocidos. Es importante entender que el enfoque de todo el libro es el de explicar cómo abordar una entrevista técnica de diseño de sistemas. Por ello, haré un breve resumen de las técnicas que se describen para afrontar dichas entrevistas.
Por otro lado, tampoco se pretende resumir el libro y mucho menos substituirlo.

Conceptos introductorios
En el diseño de sistemas se requiere de la participación de diferentes componentes más o menos complejos que permitan solventar el problema que se nos plantea. Por ello, es necesario conocer estos componentes y que papel juegan en el sistema.
En este post voy a introducir algunos de los conceptos más simples, llamémosles introductorios, que serán necesarios para explicar aquellos más complejos.
Punto único de fallo
Para mi, uno de los conceptos más relevantes y que merece una atención especial es el de Punto único de fallo (Single Point Of Failure o SPOF).
El Punto único de fallo lo podemos definir como "aquel componente que si falla, interrupe el servicio del sistema". Es por ello que es muy importante identificar y eliminar los SPOF en un sistema, ya que estos pueden tener un impacto significativo en la disponibilidad y confiabilidad del sistema. Una forma común de mitigar los SPOF es implementar redundancia, es decir, tener más de un componente o sistema en funcionamiento para proporcionar los mismos servicios. De esta manera, si un componente falla, otro componente de respaldo puede tomar su lugar y garantizar la continuidad del servicio.
Conceptos introductorios para el diseño de sistemas
Algunos de los conceptos más simples que para mi son un buen punto de partida para poder llegar a entender mínimante el diseño de un sistema son los siguientes:
- Escalabilidad vertical y horizontal.
- Nivel web, de cache y de datos.
- Sistema de nombres de dominio (DNS).
- Centros de procesamiento de datos.
- Colas de mensajes.
- Registros, monitorización y automatización.
Escalabilidad vertical y horizontal
La escabilidad de los sistemas es uno de los temas más relevantes cuando se habla de sistemas que tienen expectativas de crecimiento a corto, medio e incluso largo plazo o que simplemente tienen picos de trabajo periódicos. Tradicionalmente, se definen 2 tipos de escalado posibles:
- Escalado vertical (vertical scaling o scale up) se conoce como el de añadir más potencia de procesamiento, almacenamiento,.. a los sistemas ya existentes.
- Escalado horizontal (horizontal scaling o scale-out) se conoce como el de añadir más recursos (servidores, bases de datos,...) incrementando así la cantidad elementos dentro del sistema.
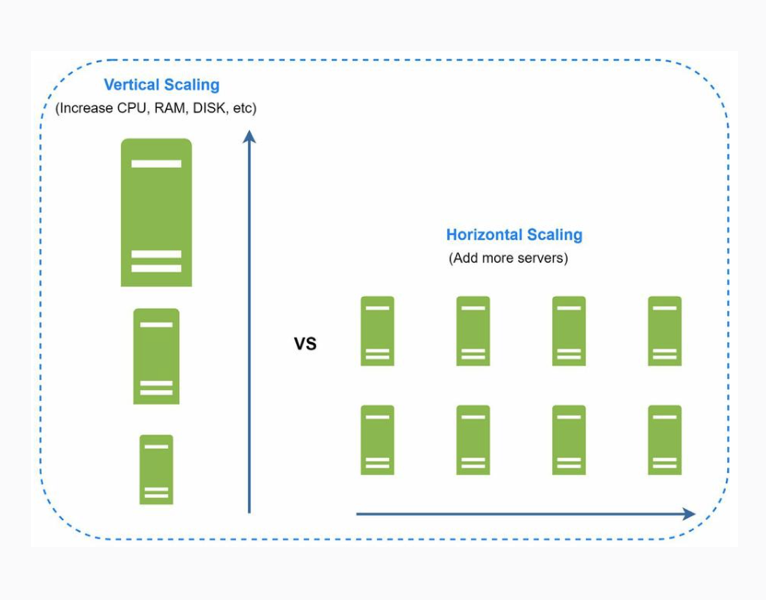
Cada tipo de escalado tiene sus ventajas e inconvenientes pero el horizontal es el más deseable para aplicaciones que requieren de un escalado mayor. Al fin y al cabo, al provisionar al sistema con más máquinas se reduce el SPOF.
Nivel web, de datos y de caché
Es una manera válida para separar un sistema complejo en subsistemas más simples. De esta manera, se puede atacar de forma aislada e individualizada tanto de forma conceptual como práctica el sistema en su totalidad.
Nivel web
El nivel web es el que cubre la comunicación y el tráfico entre los clientes (web / mobile) y los servidores. En este nivel es importante comprender siguientes conceptos:
- Balanceador de carga, también conocido como Load balancer, es el encargado de distribuir automáticamente la carga de trabajo (por ejemplo, tráfico) entre distintos servidores o aplicaciones. Los clientes se conectan directamente al balanceador de carga y es éste el que se encarga de distribuir el tráfico. Una pieza clave cuando queremos reducir el SPOF ya que este se encargará de redirigir todo el tráfico a los sistemas disponibles en caso de que algún sistema falle.
- Nivel web con estado y sin estado. Un nivel con estado (stateful tier) es aquel que recuerda los datos (state) entre las diferentes peticiones que se le hacen a éste. Por otro lado, un nivel sin estado (stateless tier) no conserva dicha información. En los servidores con estado, cada petición de un mismo cliente tiene que ser enrutada a un mismo servidor ya que el estado de éste persiste en un único lugar. Por otro lado, en los servidores sin estado se desacopla la parte de almacenamiento por lo que cualquier petición puede ser tratada por cualquier servidor. Los sistemas sin estado son más simples, robustos, escalables y mitigan en cierto modo el SPOF.
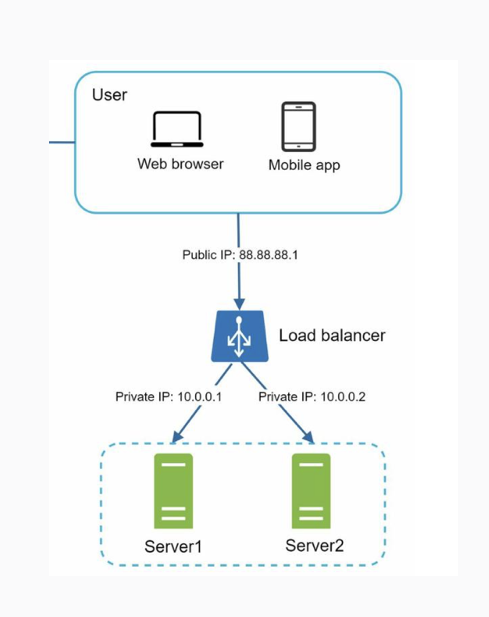
Nivel de datos
El nivel de datos incluye todo lo que a gestión de base de datos y de almacenamiento persistente se refiere. En este tier es importante comprender los siguientes conceptos:
- Tipos de base de datos. Se pueden clasificar entre las relacionales y las no relacionales. A su vez las no relacionales las podemos subdividir en: clave-valor (kew-value), grafo (graph), documentales ( document),... entre otras. Las bases de datos no relacionales pueden ser interesantes para ciertos requisitos como: baja latencia, datos desesctructurados, datos serializados (JSON, XML, YAML,...) y almacenamiento de datos masivos.
- Replicación de base de datos. La replicación de base de datos (database replication) es una técnica muy común para ofrecer una mayor tolerancia a los fallos y redundancia. Por tanto, mitigar el SPOF. La técnica más conocida y empleada es la de master-slave donde generalmente el master soporta las operaciones de escritura y los slaves soportan las operaciones de lectura.
- Fragmentación de base de datos, también conocido como sharding, es una técnica con la que conseguimos una mayor escalabilidad y descentralización al dividir los datos en bases de datos más pequeñas y por tanto, más manegables.
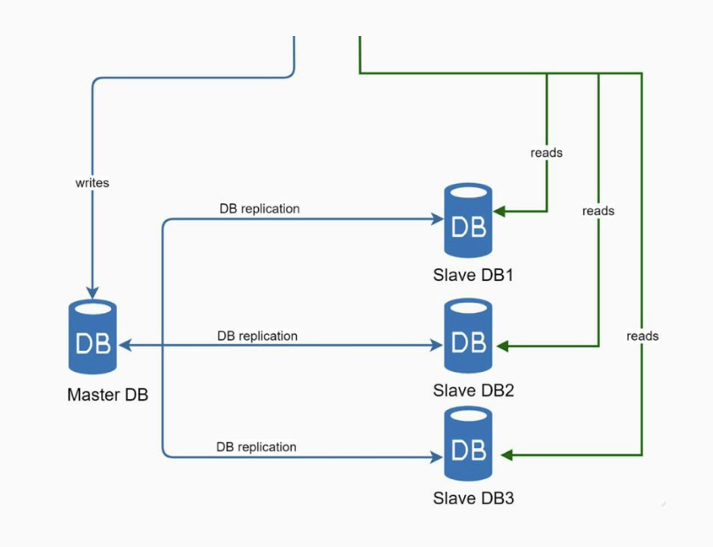
Nivel de caché
Si lo que deseamos es ofrecer una buena calidad y velocidad de carga y de respuesta estos dos componentes son imprescindibles: un nivel caché y una CDN.
En el nivel de caché se encuentran todos aquellos componentes de almacenamiento de datos, por lo general de carácter temporal, más críticos en lo que a velocidad y disponibilidad respecta. Los datos que se alojan en el nivel de caché son frecuentemente utilizados o que requieren ser consultados de la forma más rápida posible.
Es importante considerar cuándo usar caché, con que política de expiración, cómo mantener la consistencia, cómo mitigar los fallos y, en algunos casos, qué política de reemplazo utilizar. Implementar un buen nivel de caché provisionado con múltiples subcomponentes, reduce el SPOF.
Red de distribución de contenidos
Aunque una Red de distribución de contenidos (Content Delivery Network o CDN) técnicamente no pertenece al nivel de caché funcionalmente lo es. Al fin y al cabo, una CDN es una caché de contenidos estáticos: imágenes, videos, ficheros,...
Al igual que sucede con la caché, es importante tener en consideración en que casos usarla debido al coste económico que tiene asociado, qué política de expiración utilizar, qué hacer en caso de fallo, qué política de invalidación usar y con qué criterio,...
Sistema de nombres de dominio (DNS)
El Sistema de Nombres de Dominio (Domain Name System o DNS) es un sistema de gestión de nombres de dominio en Internet. Su función principal es la de traducir (resolver) nombres de dominio a direcciones IP, lo que permite que los usuarios accedan a sitios web escribiendo nombres de dominio en lugar de direcciones IP.
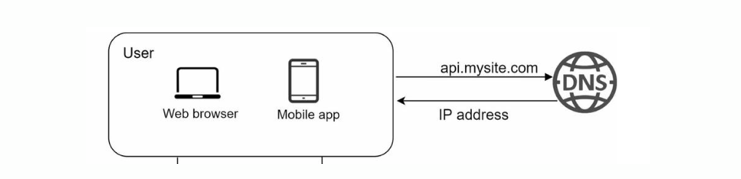
Centros de procesamiento de datos
Un centro de procesamiento de datos, también conocido como data center, es el lugar dedicado a alojar y mantener los servidores y otros subsistemas de forma parcial o completa.
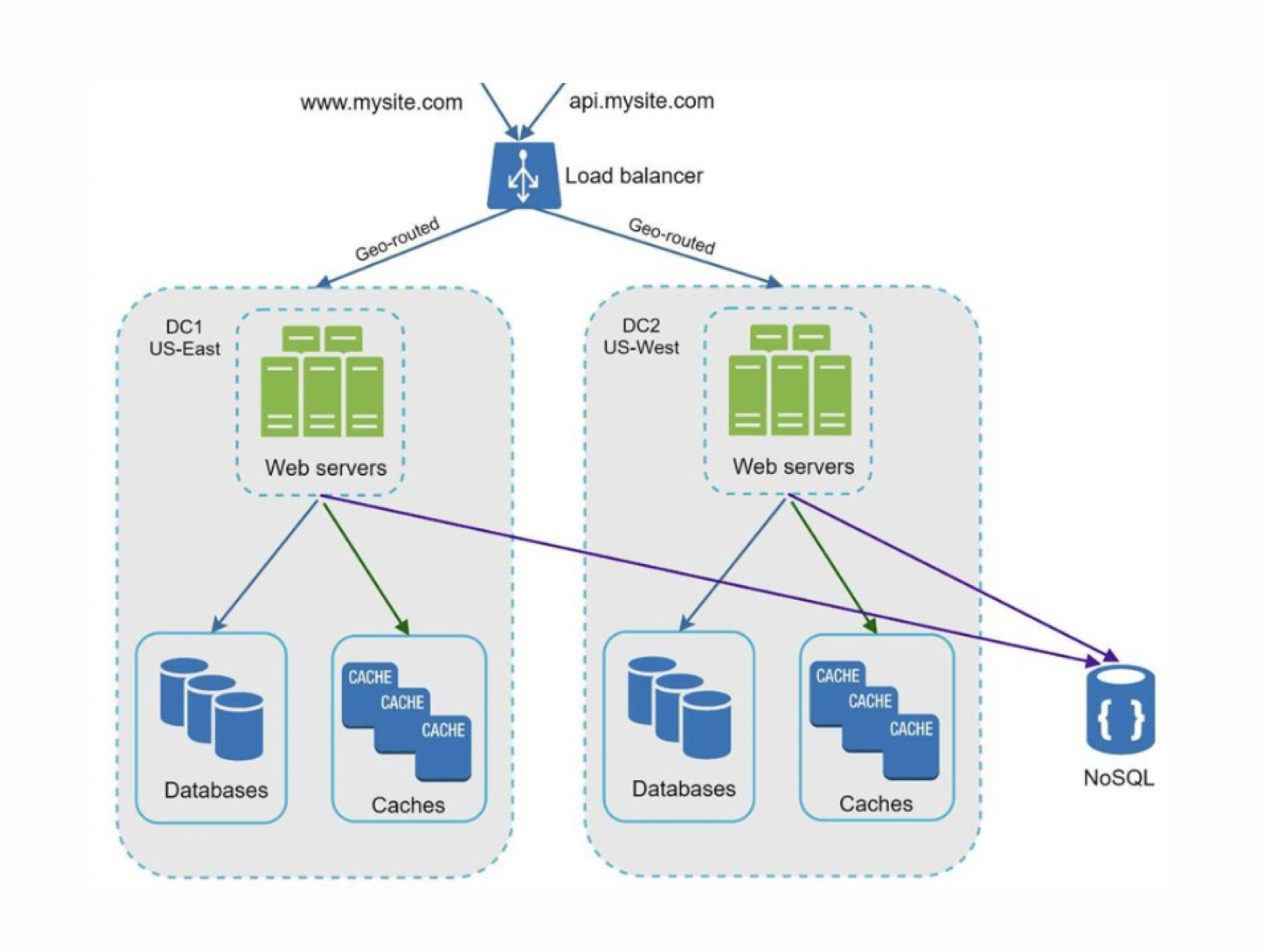
Lo más relevante aquí es lo que ofrece aplicar una redundancia de estos. Al disponer más de un centro de datos, si uno o más de estos queda fuera de servicio se puede seguir ofreciendo operando. Cabe destacar para que esto sea efectivo es necesario que haya un desacoplamiento de diversos componentes del sistema para que estos puedan escalar independientemente reduciendo así el SPOF.
Colas de mensajes
Se podría decir que las colas de mensajes, también conocido como message queues, son un componente clave para la comunicación asíncrona de los componentes de sistema reduciendo el acoplamiento de estos.
Una arquitectura basada en colas de mensajes dispone de componentes que producen mensajes (producers) y componentes que los consumen (consumers). Los producers publican mensajes en la cola y los consumers suscritos a ésta los consumen.

Este patrón de diseño reduce el acoplamiento dentro de la arquitectura ayudando a construir sistemas más escalables y fiables, favoreciendo así la reducción del SPOF.
Registros, monitorización y automatización
A medida que el sistema y el producto crece es necesario invertir tiempo en el desarrollo de estas herramientas esenciales:
- Registro, registrar los errores del sistema ayuda a identificarlos y solventarlos de forma más efectiva.
- Monitorización, recolectar información del sistema y del producto puede ayudar a entender y plantear los siguientes pasos para hacer crecer el proyecto.
- Automatización, con el crecimiento del sistema y del producto es necesario automatizar ciertas tareas para aumentar la productividad tanto del producto como del equipo de desarrolladores.
RPO y RTO
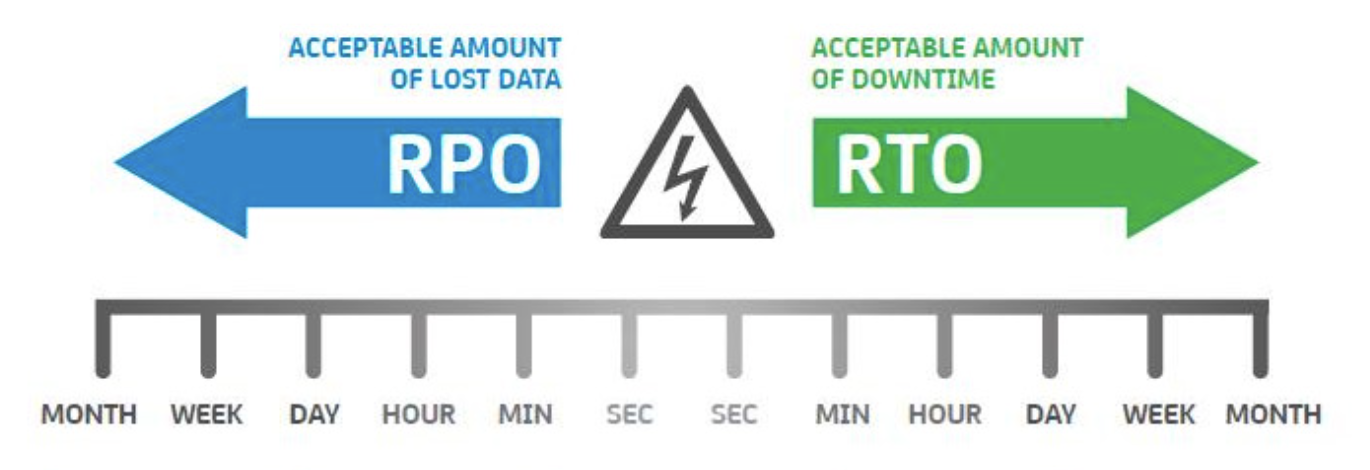
Cuando ocurre un fallo en nuestro sistema es importante tener en cuenta estos dos conceptos:
- RPO (Recovery Point Objective). Es el punto en tiempo hasta el cual se deben recuperar los datos en caso de un fallo. Por tanto, es la cantidad de tiempo o volumen de datos que un sistema puede permitirse perder en caso de un incidente. Para mitigar es necesario disponer de copias de seguridad y/o replicación de datos. Todo dependerá del tipo de la naturaleza del negocio.
- RTO (Recovery Time Objective). Es el tiempo que se estima que se tardará en recuperar el sistema después de un fallo. Por tanto, es el plazo en el que se espera que el sistema esté operando de nuevo después de un incidente. Para mitigar es necesario disponer de un plan de recuperación frente a incidentes que se apoye en sistemas de redundancia y de restauración de datos.
Aprendizaje
Estos para mí son los conceptos más básicos que has de conocer antes de aventurarte a diseñar un sistema. Si quieres leer y aprender más sobre este libro, este post hace referencia principalmente al capítulo: “Chapter 1: Scale from zero to millons of users”. Puedes conseguir el libro aquí.